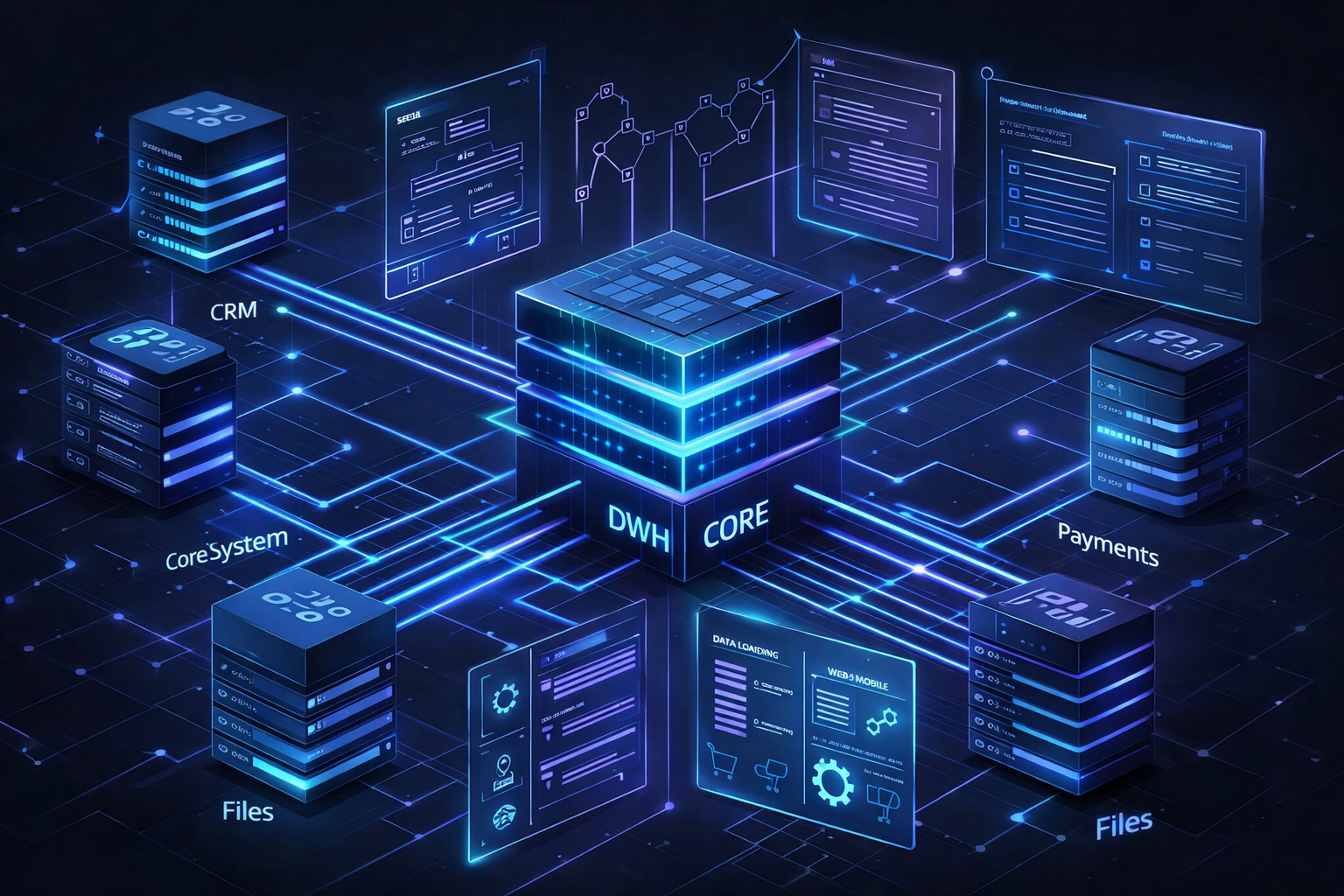
Крупная финтех-команда запускала централизованное хранилище данных. Нужно было собрать разрозненные источники в единый контур и договориться о правилах, загрузки, историзации и использования в витринах различной информации. В таких проектов «просто сложить все в DWH» не работает. Без спецификаций и модели команда упирается в противоречия и постоянные переработки.
Компания iStaff-it, занимающаяся кадровым аутстаффингом, подключила к проекту специалиста по DWH. Он закрыл аналитический слой и помог довести требования и модель до реализации потоков данных на Apache Spark.
Задачи проекта
Нужно было спроектировать DWH и выстроить корректную интеграцию/миграцию данных из систем-источников. А еще — подготовить понятные артефакты для разработки. Эксперт, работающий по договору аутстаффинга, должен был:
- собрать и уточнить требования у стейкхолдеров и закрепить их в документации;
- проанализировать источники: структуру, ключи связности, качество, дубли, пропуски;
- провести анализ разрывов (GAP-анализ) и описать правила трансформаций;
- построить модели данных (концептуальную, логическую, физическую);
- спроектировать ядро DWH на Data Vault 2.0 и проверить реализуемость;
- участвовать в реализации загрузок и контролировать корректность результатов.
Проектирование DWH с интеграцией данных из ряда источников потребовало детальной проработки требований, построения модели на Data Vault 2.0 и трансформации данных с учетом GAP-анализов. Наш специалист обеспечил четкое описание процессов, что позволило ускорить реализацию и минимизировать риски.
Роль нашего аутстафф-специалиста
Эксперт компании iStaff-it четко зафиксировал требования и подготовил спецификации для разработки, обеспечив согласованность действий между командами заказчиков. Он провел GAP-анализ, выявив слабые места в источниках, и определил, какие трансформации данных требуются для их интеграции в систему.
В процессе реализации специалист контролировал корректность потоков данных и их соответствие первоначальным спецификациям. Работая с девелоперами и архитектором, он обеспечил настройку процессов загрузки, что позволило избежать ошибок и ускорить вывод на этап эксплуатации.
Требования, спецификации и согласование логики
Чтобы разработка не «выдумывала правила» по ходу, эксперт сформировал управляемый контур требований:
- описал бизнес-сущности и атрибуты, критерии готовности данных и граничные условия;
- подготовил спецификации для разработки: маппинги, форматы, правила обновлений и историзации;
- завел единый порядок управления изменениями: что считается правкой требований, как согласуем, где фиксируем.
В результате команда, которая приняла решение нанять разработчика по договору аутстаффинга, получила понятный набор артефактов. На них можно было опираться при реализации витрин и загрузок — без многочисленных повторных согласований по кругу.
Анализ систем-источников и GAP-анализ
До моделирования важно понять, что реально есть в источниках, а где ожидания бизнеса расходятся с данными. Поэтому специалист:
- оценил варианты интеграции по каждому источнику (подключение, перенос, промежуточные слои);
- разобрал ключи связности и «слабые места» качества: дубли, пропуски, несогласованные значения;
- описал правила трансформаций и контроль качества, чтобы проблемы не переезжали в DWH «как есть».
По ходу анализа источников эксперт выявил несоответствия между данными и требованиями бизнеса. Благодаря GAP-анализу, он определил недостающие поля, слабые места в качестве данных и необходимые трансформации для корректной интеграции в DWH.
Модели данных и Data Vault 2.0
Специалист iStaff-it собрал целевую модель на трех уровнях: от концептуального до логического и физического. Ядро корпоративного хранилища данных было спроектировано в Data Vault 2.0. Эксперт:
- выделил Hubs под устойчивые бизнес-ключи, Links под связи доменов, Satellites под атрибуты с историзацией;
- задал единые правила трассируемости (источник записи, даты загрузки/изменения, контроль уникальности);
- заложил расширяемость, чтобы подключение новых источников не ломало уже построенный слой.

Так, у заказчика, решившего взять программиста в аренду, появился надежный «каркас» DWH, который можно наращивать без постоянных переделок модели.
Реализация потоков данных на Apache Spark
На этапе внедрения специалист участвовал в реализации потоков данных и помогал держать корректность:
- описывал логику преобразований в Spark (join-цепочки, фильтрации, агрегации, обработка поздних данных);
- согласовывал правила инкрементальных обновлений и переобработки, чтобы не переливать данные целиком;
- помогал проверять результаты загрузок (со сверкой объемов, контролем ключей и выборочными reconciliation-запросами).
Для снятия рисков часть логики проектировалась на SQL и Python (PySpark) — чтобы подтвердить маппинги и поведение преобразований до «боевых» прогонов.
Результат для заказчика
Клиент получил основу для развития централизованного DWH. В его распоряжении оказались согласованные требования и спецификации, понятная модель с Data Vault 2.0 и реализуемые потоки обработки данных на Spark. Команда смогла двигаться предсказуемо — меньше спорных трактовок и возвратов, быстрее вывод витрин.
Хотите усилить data-проект опытным аналитиком, инженером или архитектором данных? Наша компания занимается аутстаффингом кадров в IT! Подберем эксперта под ваш стек и задачи.